Metatron distributed Druid
Notice: Undefined offset: 1 in /data/httpd/www/html/wp-includes/media.php on line 70
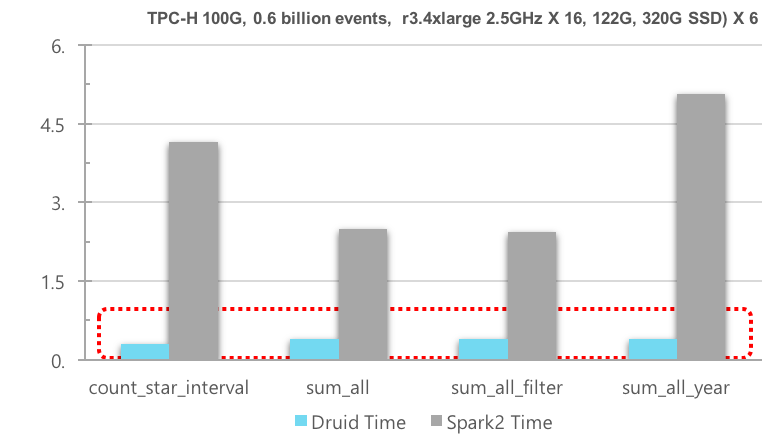
Metatron implements distributed in-memory engine based on Druid which is a high-performance, column-oriented, distributed data store. It supports users can discover insights from data intuitively and query for the massive volume of data.
Adaptation of Druid Technology
Why choose Druid?
Metatron needed an end-to-end solution that enables management of the whole process of data analysis at once. Druid was adequate for such need for the following reasons:
First is speed. Druid compiles large volumes of data in real time and performs indexing into query-able form immediately. Based on distributed processing, it aggregates big data in notably short time – a few seconds maximum.
Next is convenience. Druid’s OLAP Cube data format is time series based. It makes data analysts convenient to search, apply filters on, and visualize the data. Such easy search and flexibility enables users not to worry about queries and intuitively sort data and figure out relationships.
Third is Druid’s excellent compatibility with extensions. Users can easily add modules on Druid. Utilizing this feature, metatron established an end-to-end solution which covers all layers from compiling, saving, processing, analyzing, visualization etc.
With powerful support on data compilation and processing, Druid was an excellent choice for metatron’s engine. Other impressive strong points of Druid are described below.
- Powerful user-facing analytic applications
- Support for Sub-second OLAP Queries
- Minimize ETL processing
- Flexible schema changes
- Scalable handle trillions of events
But Druid had some limitations (As of November 2017):
- Constraints on joining data tables. Therefore, metatron uses different SQL engine for preprocessing data.
- Druid supports SQL query partially only.
- Metatron’s existing SQL engine is better for raking data.
- Cannot edit or add rows on already-indexed segments. It is possible on special occasions such as incremental ingestion, but generally it is not.
- null value not supported.
- Filtering not supported on measures.
- Unassured linear scalability. Additional servers do not lead to much improvement.
- Limited support on data types and difficult to add other types.
- Required to another segment cache in historical node, for index loading. Disk capacity required on historical node.
- Limitations of managing and monitoring tool
Metatron distributed Druid
Therefore, Metatron improved several functions as follows:
Improvements on Query performance
- groupBy Queries
- Other Queries
Additional functions
- Virtual columns (map, expression. etc.)
- Metric type extension (double, string, array, etc.)
- Formula function extension
- Able to export result data from Druid queries to HDFS of files
- Added query types for meta information or statistics
- Added aggregate functions (variance, correlation, etc.)
- (limited) Added window functions (lead, lar, running aggregations, etc.)
- (limited) Added join function
- (limited) Added subqueries
- Added temporary data sources
- Added complex queries (datasource summary, correlation between data sources, k-means, etc.)
- Provide grouping-set, pivot in group-by query
- Provides GIS related functions(geographical server adapter)
- Provides histogram by each columns
- Provides Bit-slice indexing functions
Improvements on index structure
- Histogram for filtering on metrics
- Supports lucene format for filtering texts
- Added compact r-index
- (experimental) Supports lucene indexing / filtering (gis, text)
- (experimental) Supports BSB indexing for numeric types
Supports on Synchronization with Other Systems
- Hive storage handler
- Hive table ingestion (connected with Hive meta-store)
- ORC format ingestion
- RDBMS data ingestion through JDBC
- (limited) Supports Backport SQL
Miscellaneous Improvements
- Bug fixes (+50), additional functions and other minor improvements
One Response
[…] LEARN MORE […]