What to keep in mind when ingesting a data source to Druid from Metatron Discovery
Notice: Undefined offset: 1 in /data/httpd/www/html/wp-includes/media.php on line 70
Getting data into a druid is not an easy job. This is especially difficult for those who are new to Druid. You have to set up unfamiliar options such as segment and granularity. And it is not easy to find out why when ingestion fails. So, today, I’ve just made a point of what to keep in mind while creating a data source.
Creating a data source
What is a data source?
It is a unit of data contained in the druid, the data processing engine of Metatron Discovery. If you want to analyze your data with Metatron Discovery, you must add data to the Druid.
Where can I get the data?
There are six ways to load data sources.
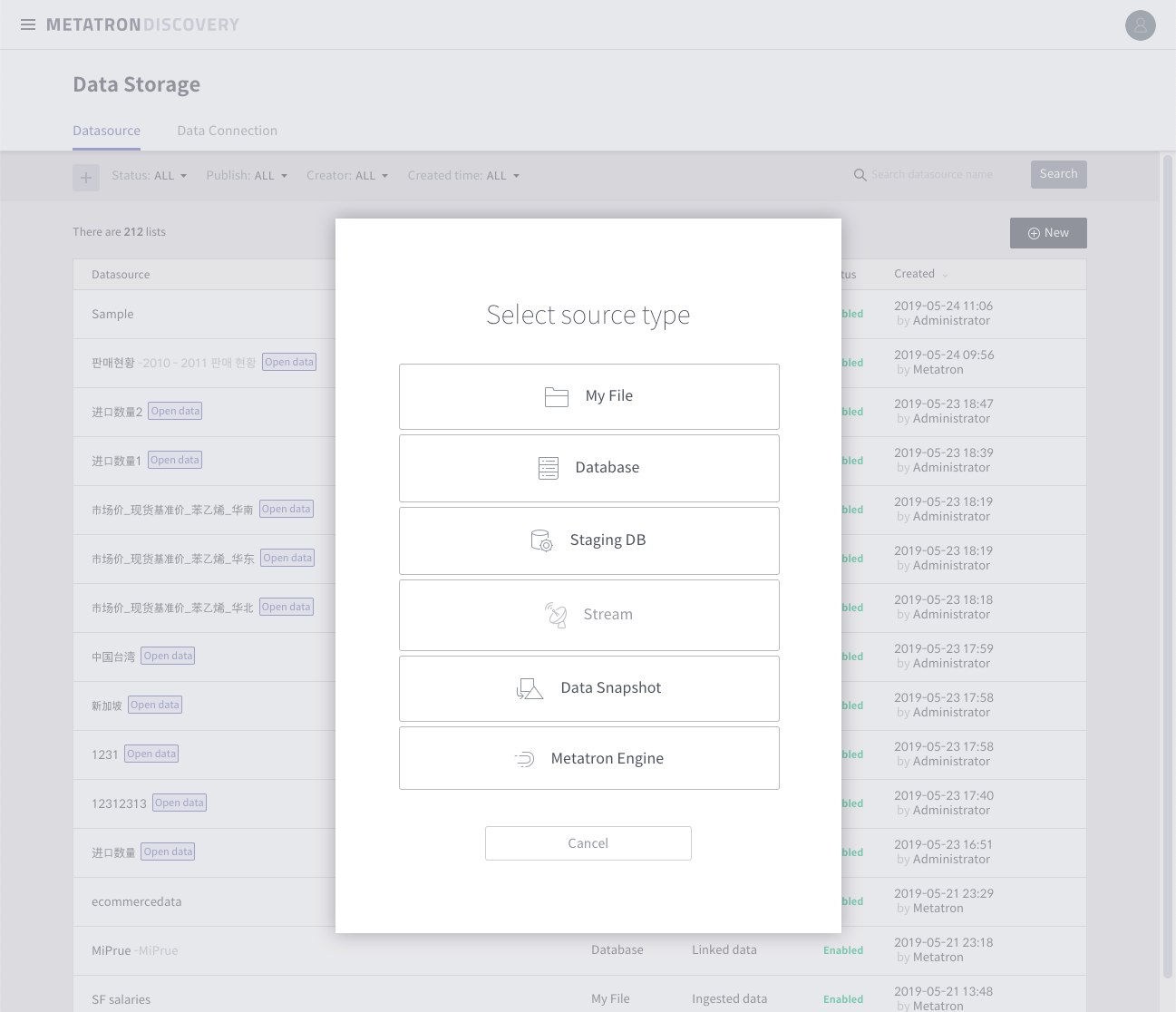
- File Load files (.csv, .xlsx) stored on your personal computer
- Database Load data from jdbc method from SQL engine
- Staging DB Load large amounts of data from Druid’s staging DB (mostly Hive) via MapReduce
- Stream Real-time loading of data coming in via Kafka
- Data Snapshot Loading from the result of processing in data preparation
- Metatron Engine Load data from another version or already installed druid engine
The Staging Database is the intermediate waypoint for data loading. Druid uses Hive as staging. Importing data from staging db means importing the data table already created in Hive.
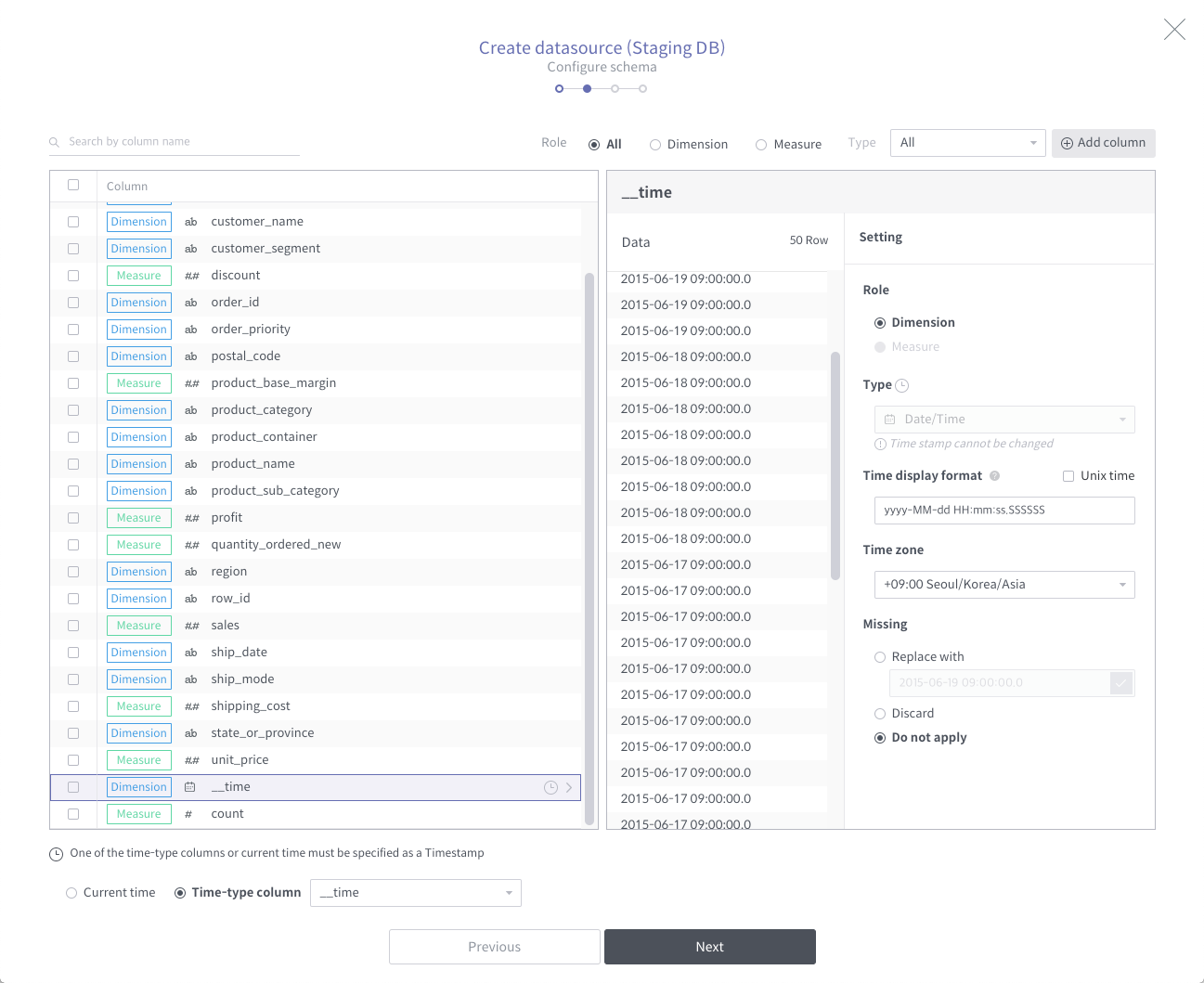
Setting up the data source schema
Next, you need to specify the role for each column. If you look at a sample of data, set it to a normal dimension for strings and measure for numbers. (Not always the case.) For a description of dimension and measure here: link
The important thing in this part is that the timestamp column, which is the basis for data partitioning, is a must, and the time representation must match the data. Otherwise, the load will fail with a high probability.
Setting the druid ingestion options
Next, set the data source loading options in detail. The defaults are set, but you need to fix them for your own data.
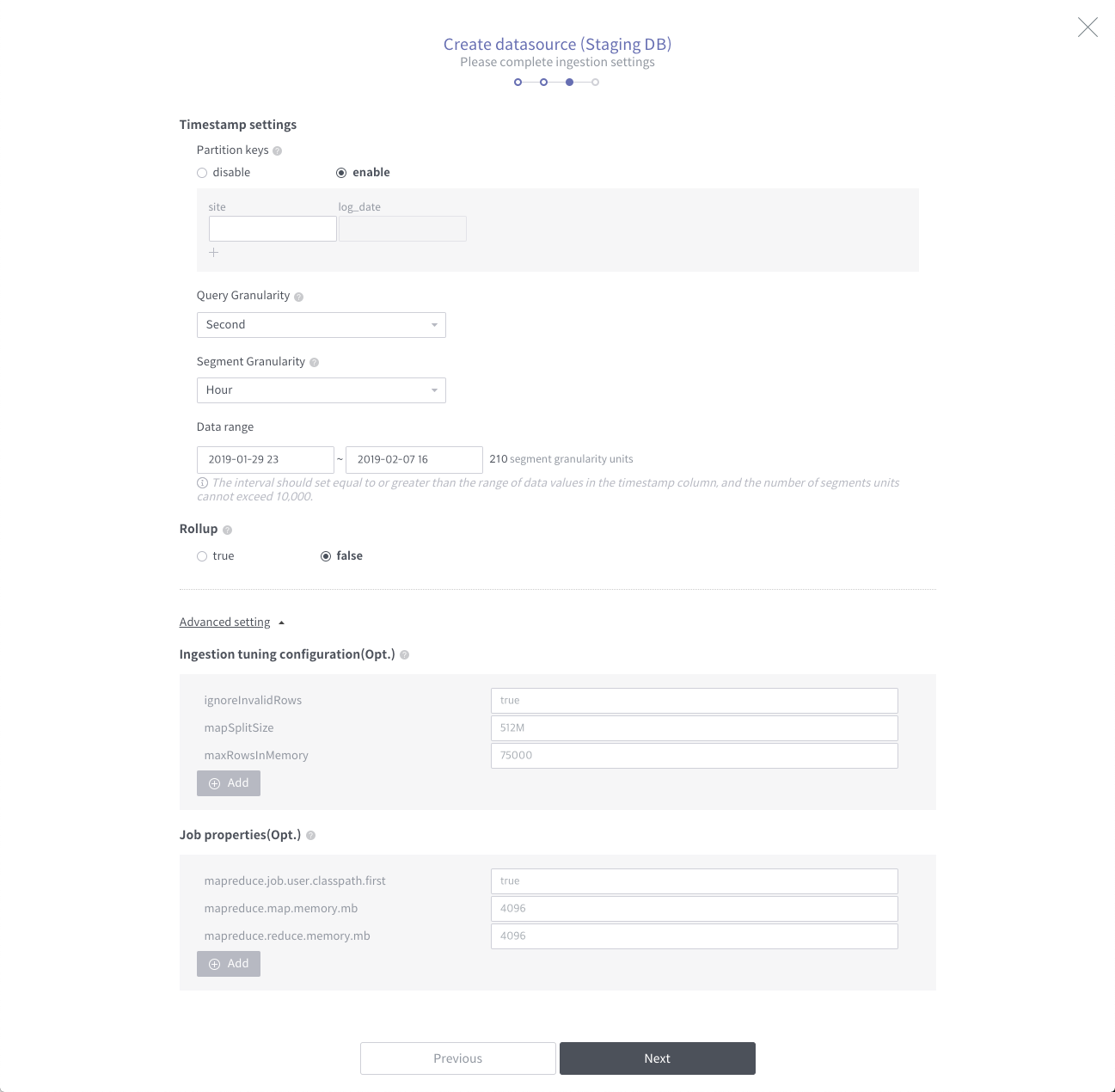
- Partition keys If partition key exists in Hive table, it is possible to set to load only specific partition data
- Query Granularity Unit of data query
- Segment Granularity Data separation unit for distributed processing
- Data Range A setting that limits the range of data to load on a periodic basis. The number of reducers is determined later in the mr job.
- Rollup Whether data pre-aggregation is set when loading data. If you want the data source to be saved as it is, you can disable it. If you need query performance, you can enable it.
- Advanced Setting Other settings can be added in json format. The classpath setting due to a library conflict issue is mainly used, and the memory setting due to an out of memory issue is frequently used.
Later, when you enter the name and description of the data source, you begin to create the data source.
Summarize
To summarize, when you create a data source, you must match the actual data with the type of data column you are setting up. Note the timestamp format in particular. Also remember that you may need to set the classpath or memory when you set the druid ingestion option.
In the next post, I’ll see what you need to know when loading fails. Let’s meet again!