How to deal with druid data ingestion failure
Notice: Undefined offset: 1 in /data/httpd/www/html/wp-includes/media.php on line 70
In a previous post we looked at how to put data into a druid via Metatron Discovery, and summarized some things to note.
This time, I’ll show you how to deal with data ingestion failures.
Check for data source load failures
When you create a data source in Metatron Discovery, a new list item is created in the “Data Storage> Data Source” in the Preparing state.
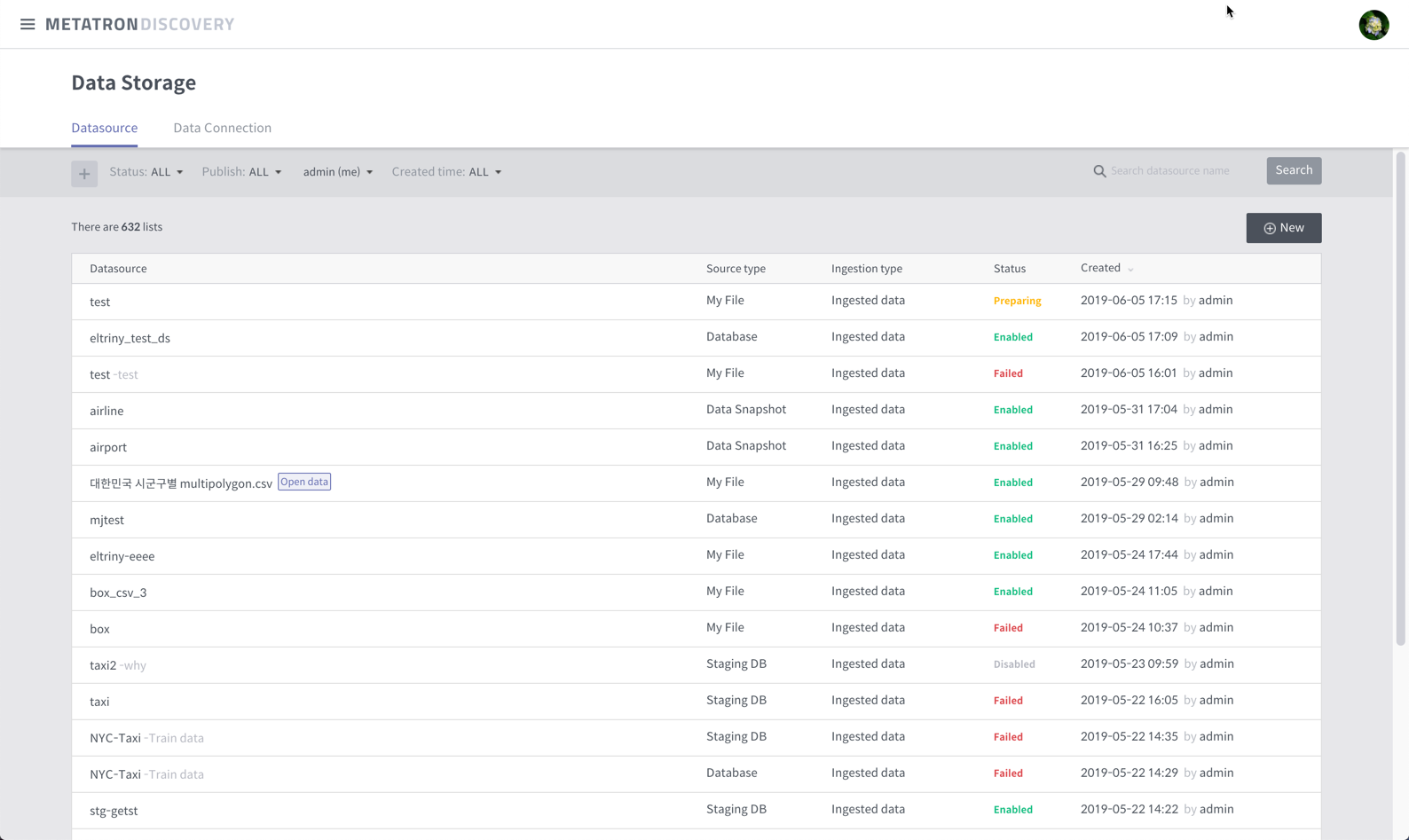
Click on the data source list to enter the detail window and you can check the status of the load in real time. If the data source load status is fail, or if you are still in the preparing state over time, then there is a problem loading the data source.
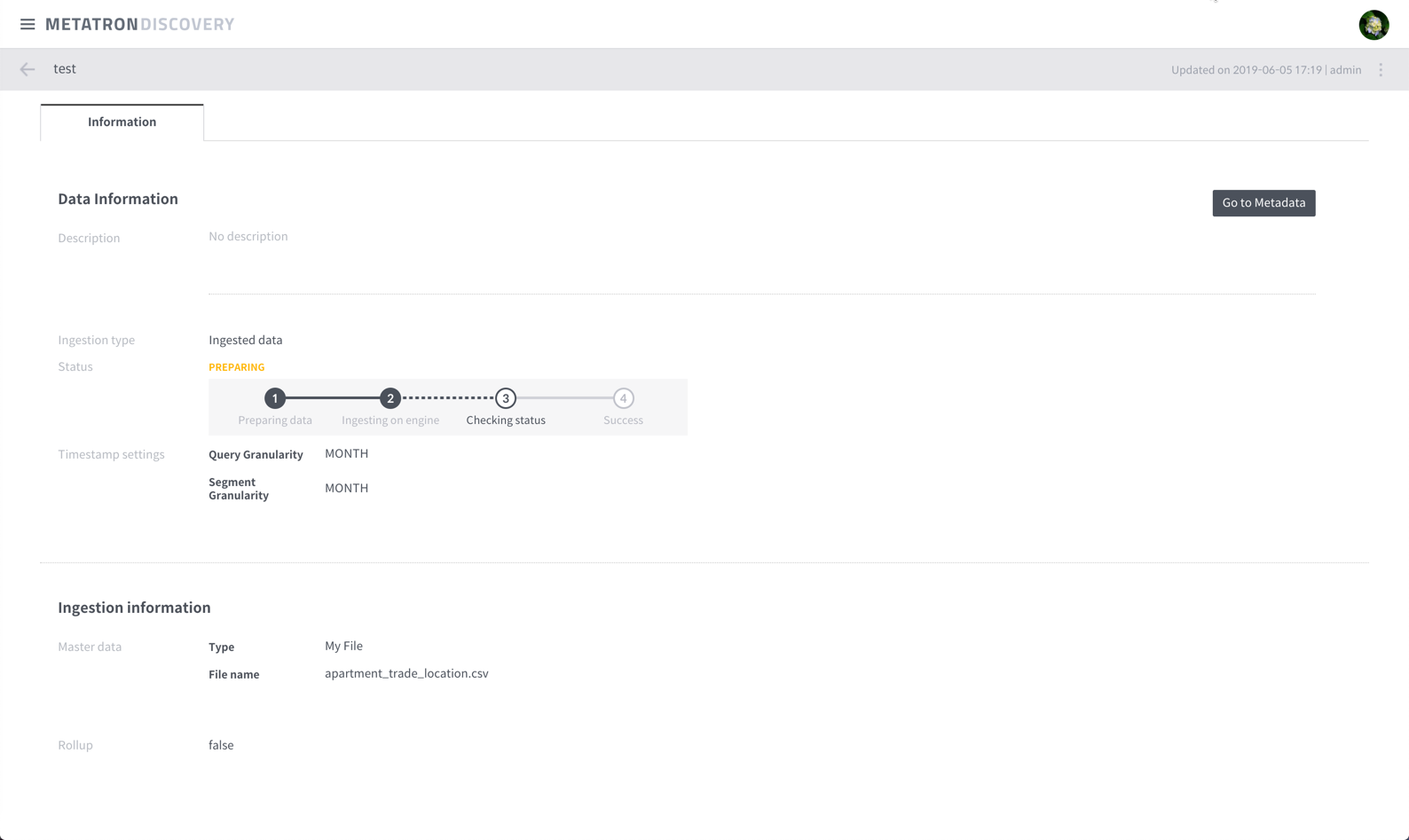
There are two things you need to know to figure out what the problem is.
- Druid ingestion task
- Hadoop Map Reduce job
Checking Druid ingestion task status
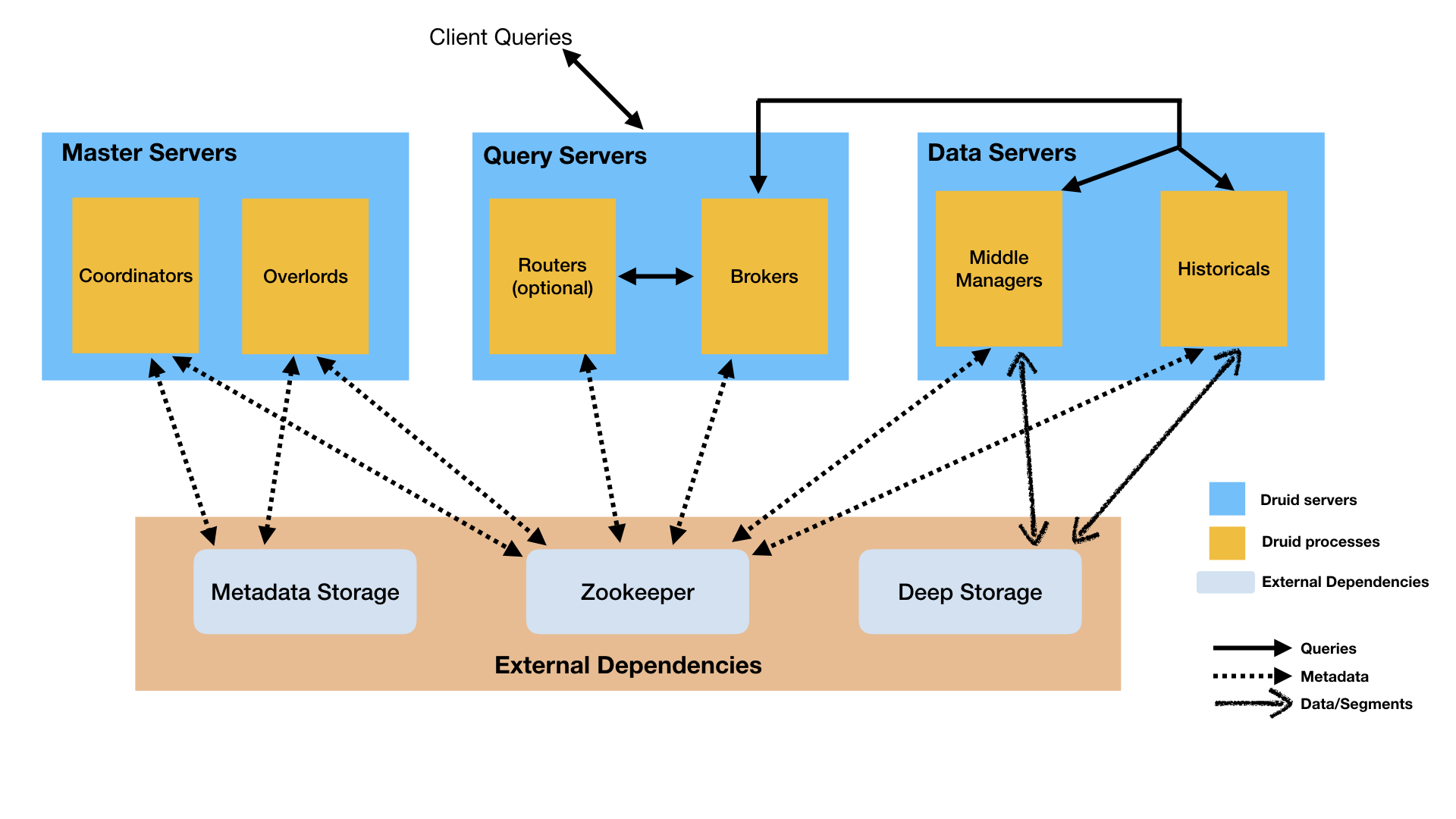
There are five node types in the druid.
- Coordinator processes manage data availability on the cluster.
- Overlord processes control the assignment of data ingestion workloads.
- Broker processes handle queries from external clients.
- Historical processes store queryable data.
- MiddleManager processes are responsible for ingesting data.
The overload manages the ingestion of data. So if you have a problem with ingestion, you should check the detail log on the druid’s overload console. The port of the overload console is set to 8090 by default. Find your data source task and see detail logs from it.
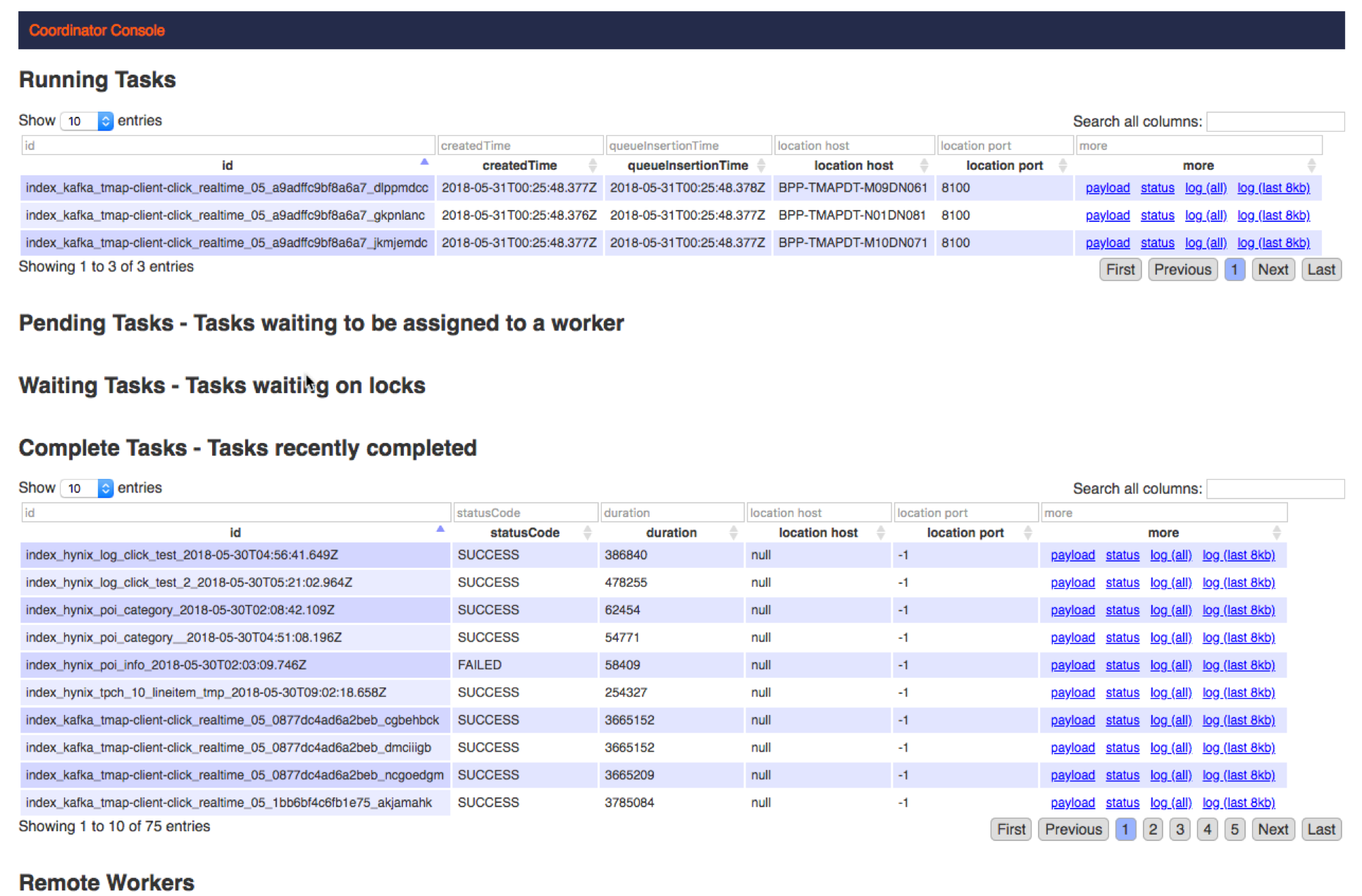
If you can’t access to the server, you can easily check the log in the Datasource details. If you search by “error”, detailed error message can be retrieved.
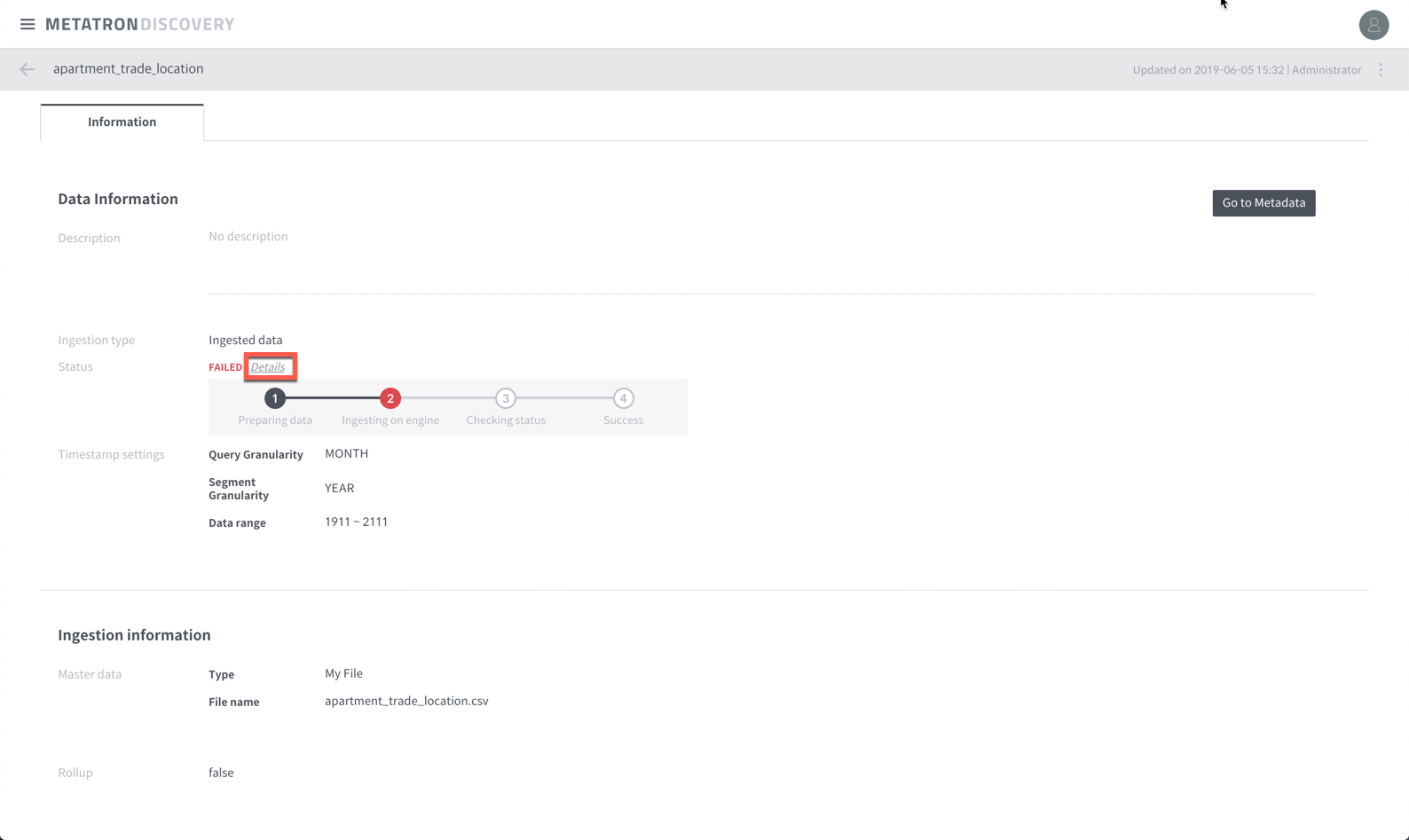
If it is an “index” error, it may occur because there is a record whose type is not correct or null. In this case, you can fix the problem by taking a snapshot with “HIVE” after preprocessing the data using the data preparation feature of Metatron Discovery. I’ll handle this case later with another post.
2019-06-05T07:42:39,744 ERROR [task-runner-0-priority-0] io.druid.indexing.overlord.ThreadPoolTaskRunner - Exception while running task[HadoopIndexTask{id=index_hadoop_apartment_trade_3_2019-06-05T07:41:30.109Z, type=index_hadoop, dataSource=apartment_trade_3}] If the overload task appears to be successful but still the data source state is preparing, make sure the data source is created in the druid’s coordinator (port number is 8081).
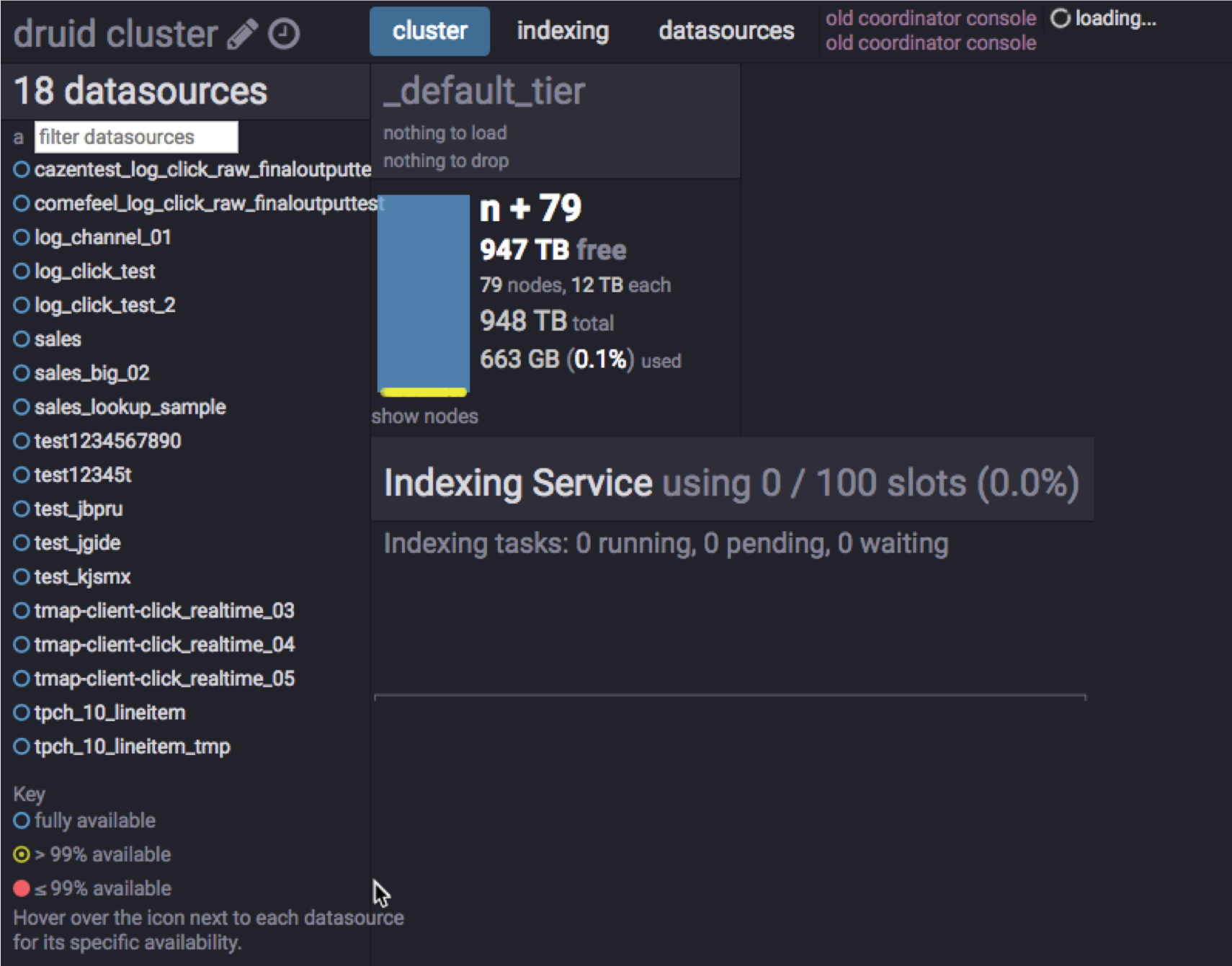
Even if the task is terminated normally, there may be cases in which no data is available due to an error in the parsing rule. Check that the delimiter is set correctly or whether the timestamp format matches when ingesting the data source.
Checking Hadoop Map Reduce job
But if the reason for the fail occurs in the MR job and you can not see it in the overlord log, you should check the Hadoop YARN log now.
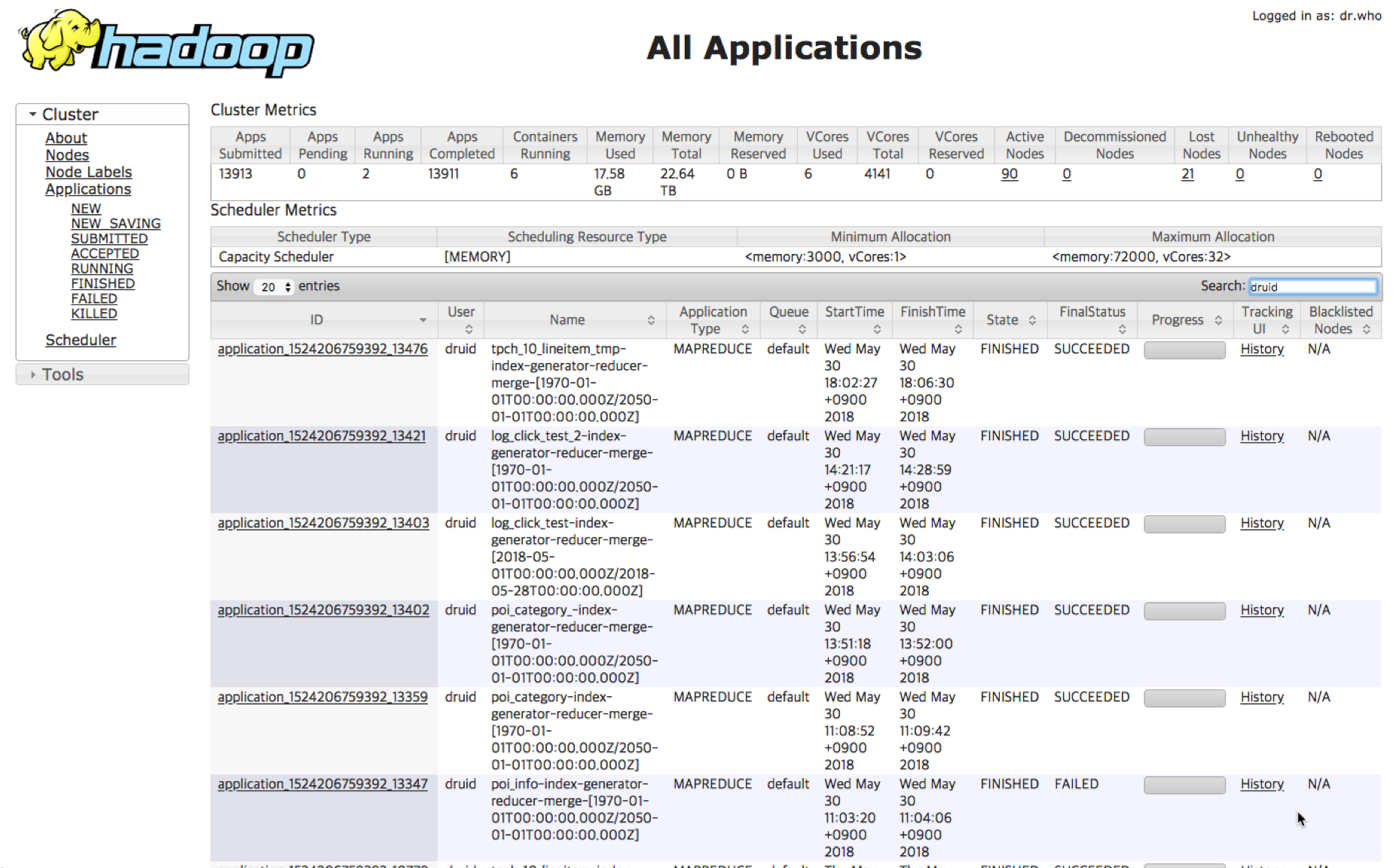
You have to go through the log to figure out the problem, fix it and try again. In particular, it is a good idea to check if there is a sufficient number of mapper, that there is not enough memory to stop the operation, or if the library load has failed.
If we have enough error experience in the future, we will try to summarize the possible trobleshooting when loading the data source. If you have a problem right now, please feel free to contact us in our discussion channel.