Using Apache Spark in Data Preparation
Notice: Undefined offset: 1 in /data/httpd/www/html/wp-includes/media.php on line 70
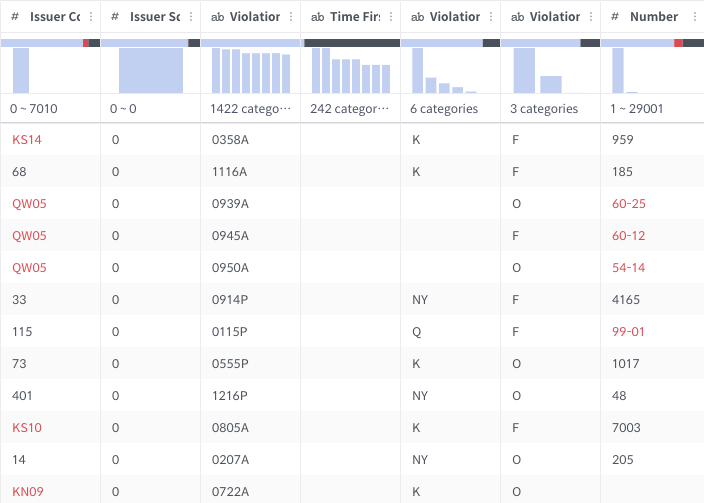
Recently, Discovery Spark Engine has been introduced in Metatron Discovery. It is an external ETL engine based on Spark SQL. The embedded engine suffers huge garbage collection pressure if the record count reaches more than 1M.
In this case, Discovery Spark Engine is the best solution. To avoid complex dependency problems, Discovery Spark Engine is designed not to require any Spark pre-installations. It just uses Spark SQL (a.k.a. data frames) and Spark Core via Maven dependencies. Of course, you can connect to your own Spark cluster to increase the performance or for integration purposes.
Apache Spark is very fit for self-serviced data preparation because it optimizes inefficient or meaningless transformation with its whole-stage code generation feature so that users can just focus more on the results than on the efficiency.
For example, if you 1. create a column, 2. delete it, and 3. create another column, then the Spark engine skips 1 and 2.
For another example, if a user changes the column’s values, again and again, Spark optimizes those transformations by:
- When some stages are meaningless, skipping them.
- When some stages can be merged by modifying calculations, reducing those stages.
Let’s get started! This post is in this following order:
- Run Metatron Discovery.
- Download the sample file.
- Setup Discovery Spark Engine and Metatron DIscovery.
- Import the sample file.
- Add transform rules.
- Create a snapshot using Discovery Spark Engine.
- Create a Datasource using the snapshot.
Run Metatron Discovery
Data preparation is a feature of Metatron Discovery. We need to run Metatron Discovery Properly. Please refer to https://www.metatron.app/download/installation-guide-custom-install.
Download a sample file
I’ll use one of NYC’s open data. (https://data.cityofnewyork.us/City-Government/Parking-Violations-Issued-Fiscal-Year-2014/jt7v-77mi)This is a report of parking violations issued in the fiscal year 2014.
This data definitely needs to be cleansed! The total rows are 9.1M and the file size is 1.79GB. As I mentioned before, the Embedded engine cannot handle this file.
Let’s get the CSV version. Click the “Export” button for this.
Setup Discovery Spark Engine and Metatron Discovery
Download Discovery Spark Engine from https://github.com/metatron-app/discovery-spark-engine.
git clone https://github.com/metatron-app/discovery-spark-engine.gitThen build with Maven.
cd discovery-spark-engine
mvn clean -DskipTests install
......
[INFO] discovery-spark-engine ............................. SUCCESS [ 0.218 s]
[INFO] discovery-prep-parser .............................. SUCCESS [ 3.077 s]
[INFO] discovery-prep-spark-engine ........................ SUCCESS [ 4.388 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
......Export environment variables for later use.
vi ~/.bash_profile
export DISCOVERY_SPARK_ENGINE_HOME=<WHERE YOU INSTALLED DISCOVERY SPARK ENGINE>
export METATRON_HOME=<WHERE YOU INSTALLED METATRON DISCOVERY>You shouldn’t run Discovery Spark Engine before configuring Metatron Discovery. Discovery Spark Engine has been designed to run tightly with Metatron Discovery. For your consistency and convenience, Discovery Spark Engine brings all configurations from Metatron Discovery’s configuration file. Discovery Spark Engine itself doesn’t have any configuration files.
vi $METATRON_HOME/conf/application-config.yaml
polaris:
dataprep:
sampling:
limitRows: 50000
etl:
limitRows: 10000000
spark:
port: 5300Before starting up, we need to set the user timezone to UTC.
vi metatron-env.sh
export METATRON_JAVA_OPTS="-Duser.timezone=UTC"Startup Metatron Discovery with the new configurations.
cd $METATRON_HOME
bin/metatron.sh startRun Discovery Spark Engine. I recommend you to run in a separate terminal because Discovery Spark Engine has no file logging for now.
cd $DISCOVERY_SPARK_ENGINE_HOME
./run-prep-spark-engine.sh -tLaunch your web browser and connect to http://{METATRON-DISCOVERY-HOST}:8180. If you run Metatron Discovery in the local environment, then the URL is http://localhost:8180.
Import the sample file to Data Preparation
From the top-left corner of the main page, click [MANAGEMENT] – [Data Preparation] – [Dataset]. Click “Generate new dataset”. Select “My file”. Drag & drop the file you downloaded (Parking_Violations_Issued_-_Fiscal_Year_2014.csv). Click “Next” and “Next”. Name as Parking Violations and click “Done” (or press Enter).
Add transform rules
Before we get started, I wish you to remember that whatever you do, you can do undo/redo every step. Don’t need to be panic at all! That’s what Data Preparation is for.
Let’s drop unnecessary columns first. Just select all of the columns with a shift-click and ⌘-click combination to save interesting columns:
- Registration State
- Issue Date
- Vehicle Body Type
- Vehicle Make
- Violation Time
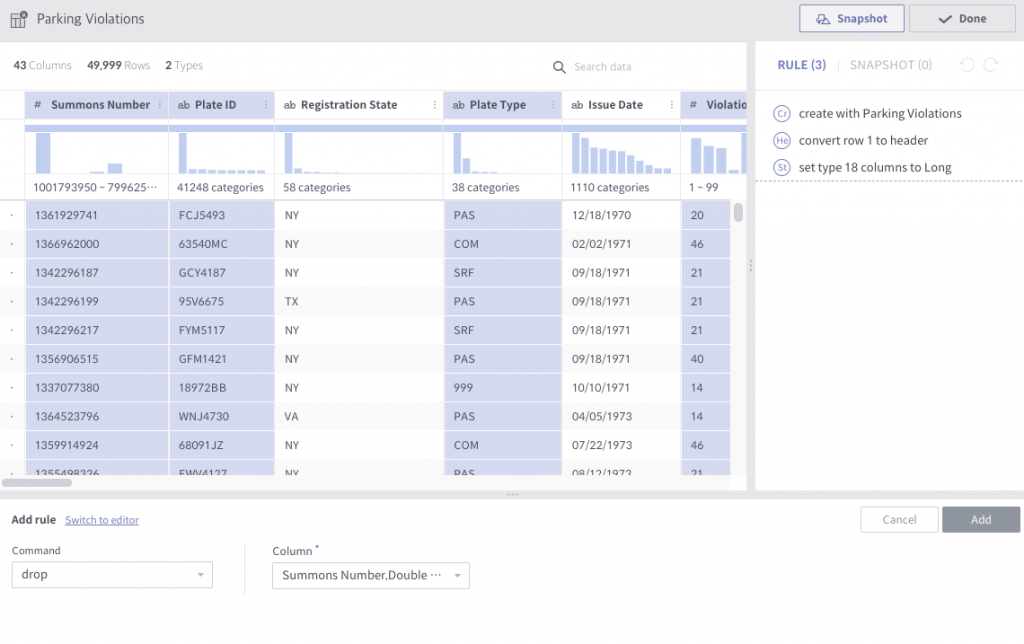
Then alter the “Issue Date” column type into the timestamp type.
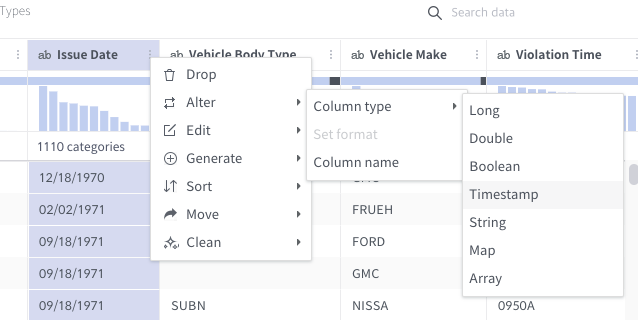
In many cases, popular timestamp formats are automatically caught. But in this case, it wasn’t. I hope it’ll be enhanced soon. Type the right timestamp format.

After that, we are going to derive a count column. This column is very useful later on.
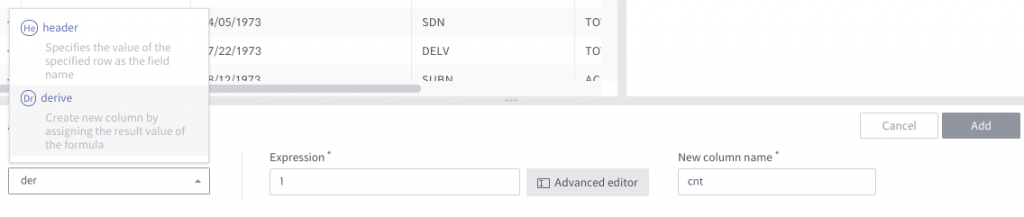
Create a snapshot using Spark Engine
Let’s create a snapshot after all the preparation jobs are done. Click the “Snapshot” button. Open “Advanced settings”. Select “Spark” as an ETL Engine. Click “Done“.
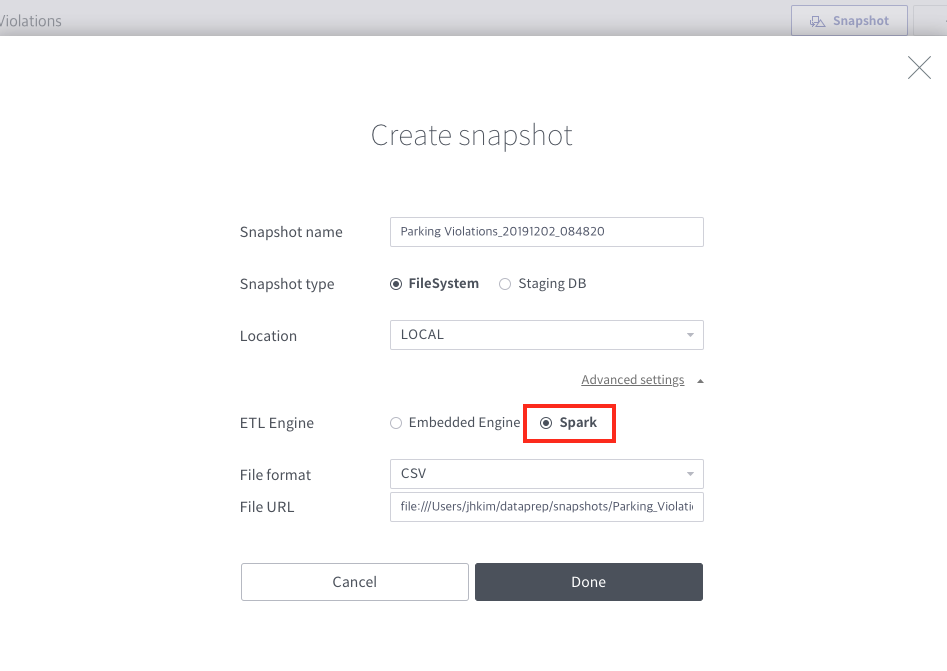
When the job succeeded, you’ll see this:
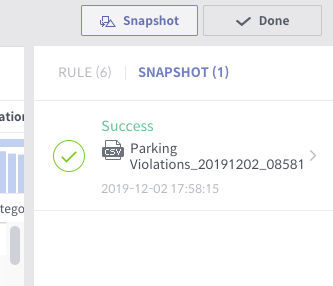
Click to see the details. Generating the snapshot took about 3 minutes on my local Mac. It will be way better in a production environment.
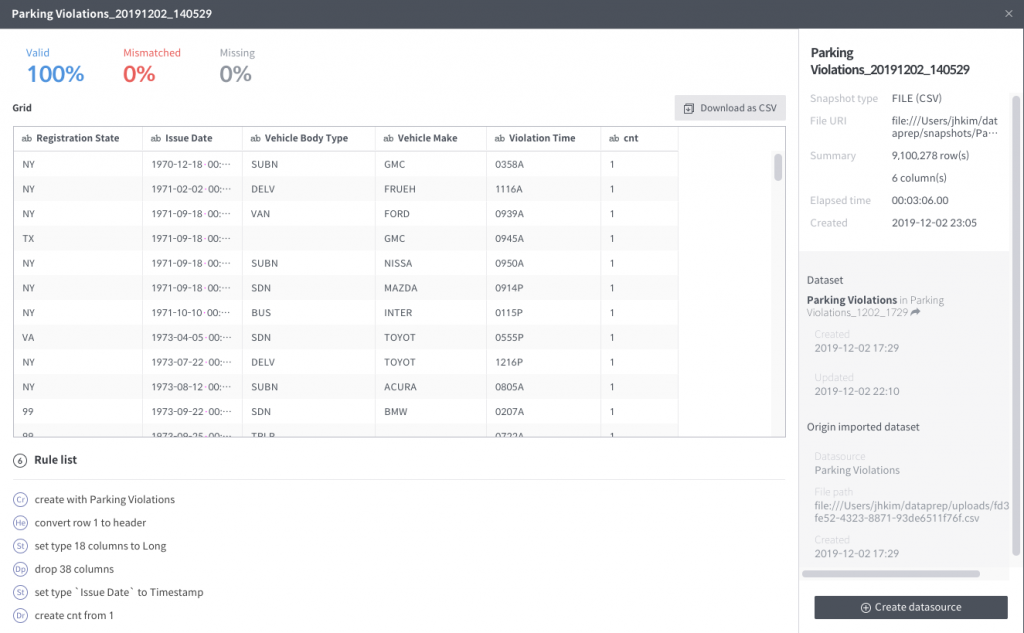
Create a Datasource with the new snapshot
Click “Create Datasource” in the snapshot details page. Then you will see this:
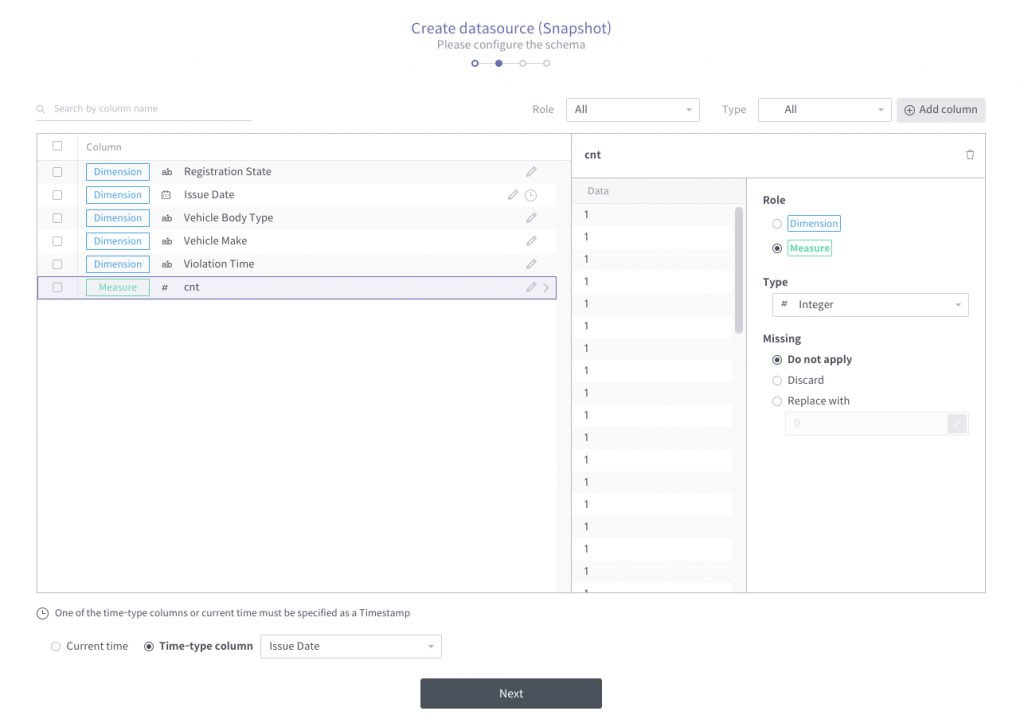
Unfortunately, we need to designate the timestamp column. If we had changed the timestamp format in a formal way, it might have been detected properly. Change type of “Issue Date” as DateTime type Dimension column (then the format will be caught automatically). The “cnt” column is numeric so its default role should be measure. This will be fixed very soon. For now, let’s change the role manually.
Click next. Set time granularity settings as below:
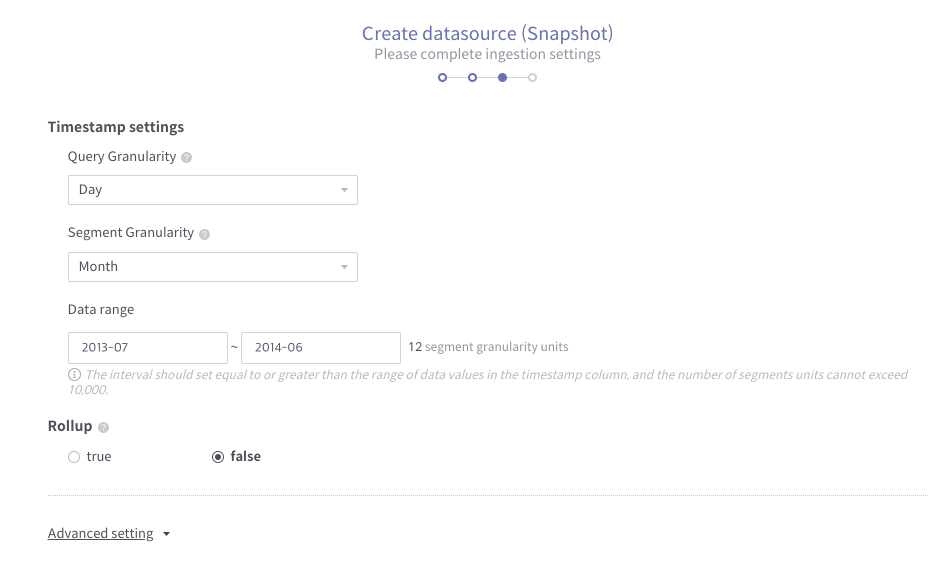
After a while you will finally see the successful Datasource like this:
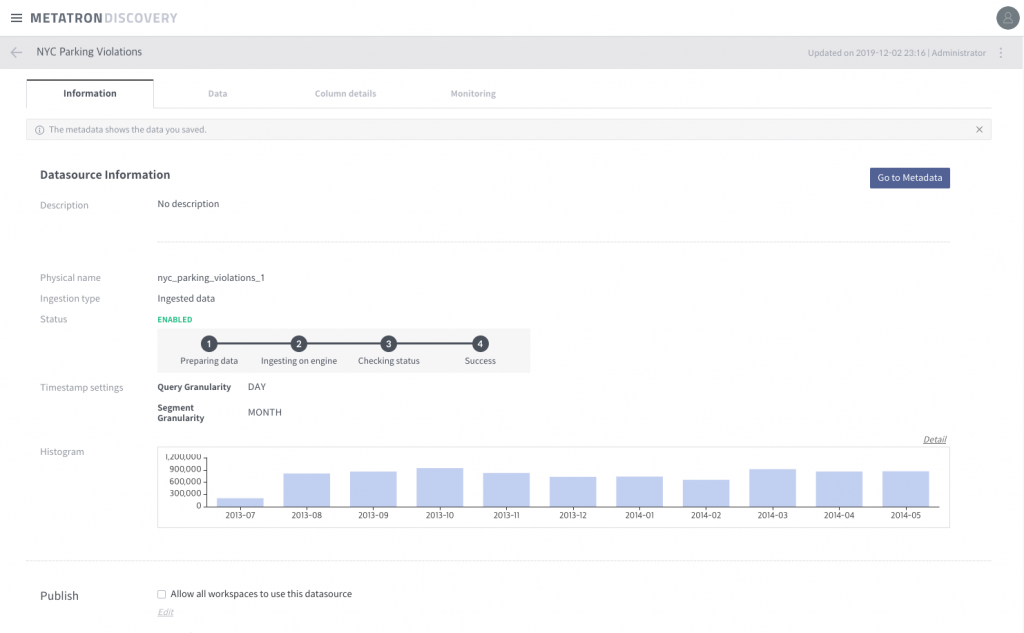
Now, you can analyze the data source you just created. For example, making workbooks and dashboards is one of the jobs you can do with it.
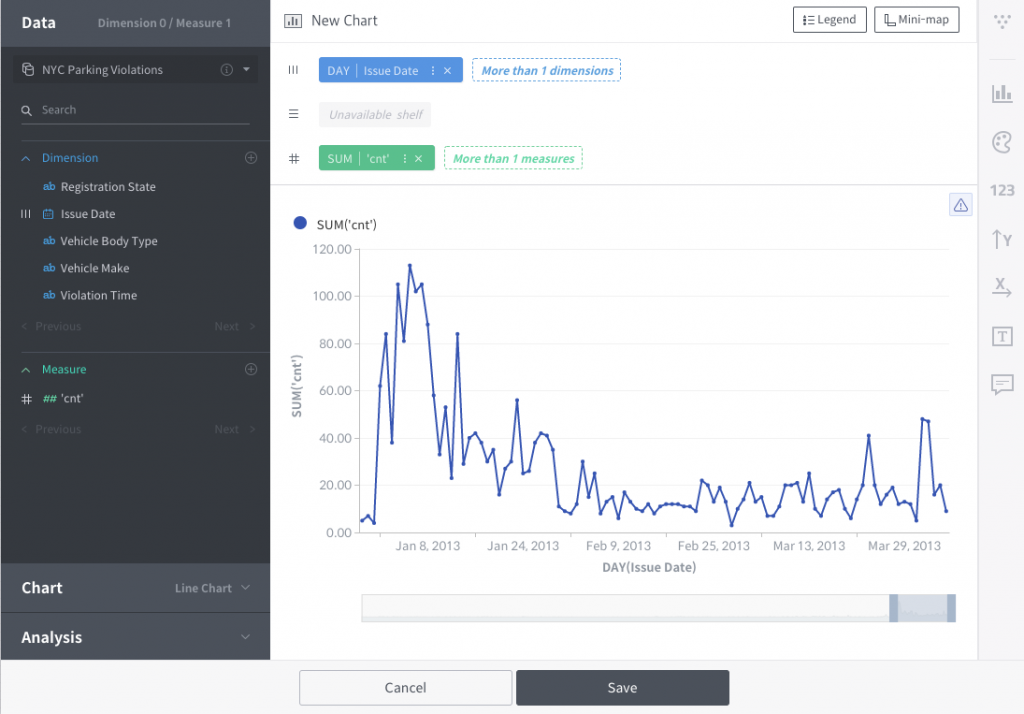
Next time, I will introduce more powerful Data Preparation transformations including multi-dataset works like join, union. Window functions will also be covered afterward.
If you have any questions, please leave a comment or email us! Thanks always using Metatron Discovery.
One Response
Hi Team Metatron,
I faced few issues while trying to embed spark as a ETL engine in metatron and in the end even after fixing those bugs, spark as a ETL was disabled in DataPrep .
I followed the given instrustion from https://www.metatron.app/2019/12/05/using-apache-spark-in-data-preparation.
Given in link:
vi $METATRON_HOME/conf/application-config.yaml
polaris:
dataprep:
sampling:
limitRows: 50000
etl:
limitRows: 10000000
spark:
port: 5300
Correction:
vi $METATRON_HOME/conf/application-config.yaml
polaris:
dataprep:
sampling:
limitRows: 50000
etl:
limitRows: 10000000
spark:
jar: discovery-prep-spark-engine-1.2.0.jar
port: 5300
Given:
application-config.yaml
Correction:
application-config.templete.yaml
Given:
metatron-env.sh
Correction:
metatron-env.sh.templete
A few changes are allso required in run-prep-spark-engine.sh.
Please let me know if anything else i could try to get spark running in dataprep.
Thanks