Data Preparation and Continuous Integration
Notice: Undefined offset: 1 in /data/httpd/www/html/wp-includes/media.php on line 70
After creating a nice dataflow, you’ll probably want to reuse the dataflow against another file or query result automatically (like daily-basis) or manually. Metatron Discovery’s data swapping feature is developed to enable this kind of works. Although Metatron Discovery itself doesn’t have scheduling ability, but you can use preptool, a CLI tool for data preparation to build the reusable data preparation process. You can use Metatron Integrator to make the repeated work easy, or you also can use crontab or your custom scheduler program.
Let’s get started with preptool. You can download the preptool from GitHub.
git clone https://github.com/metatron-app/discovery-prep-tool.git
But, in this article, because we’re going to use the fully engineered docker image that contains preptool inside you don’t need to download the preptool manually. (Refer to https://www.metatron.app/2020/01/21/deploying-metatron-with-the-fully-engineered-docker-image/)
If you’re not familiar with docker commands, using the GitHub version (in this case the docker instance is only for Metatron Discovery) is not bad, but I think copying between the docker host and guest is not that difficult. You only need to run:
sudo docker cp {local_path} metatron:{target_path}
Note that all the works in this article has been tested with teamsprint/metatron:3.4.0 docker image.
Run the metatron instance
$ git clone https://github.com/teamsprint/docker-metatron.git $ cd docker-metatron $ ./run.sh # ./prepare-all-metatron.sh (wait until prompt) # cd $METATRON_HOME # tail -f logs/metatron-*.out …Started MetatronDiscoveryApplication in 90.702 seconds (JVM running for 93.445) (wait until above) ^C #
Create a dataflow
Connect to http://localhost:18180. Get into Data Preparation > Dataset.
Select “My file”.
Drag and drop sales_2011_01.csv. You can download [[sales_2011_01.csv]] or get from /sample directory in the docker instance. All CSV files coming next are in there. If you’re not doing with a docker image, download [[sales_2011_02.csv]], [[sales_2011_03.csv]], [[sales_2011_04.csv]].
Click next or done repeatedly. Then you’ll get a dataflow like below:
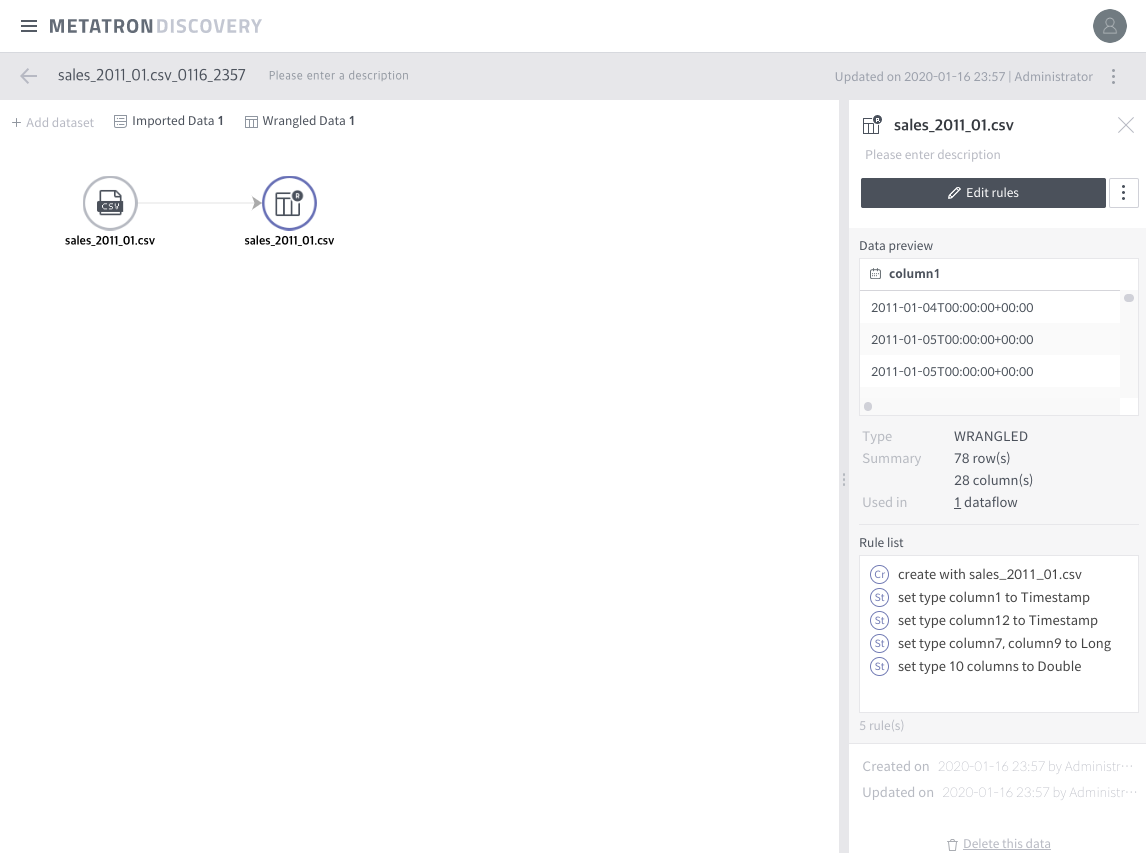
Rename the dataflow as “sales_dataflow” and the wrangled dataset as “monthly_transform”.
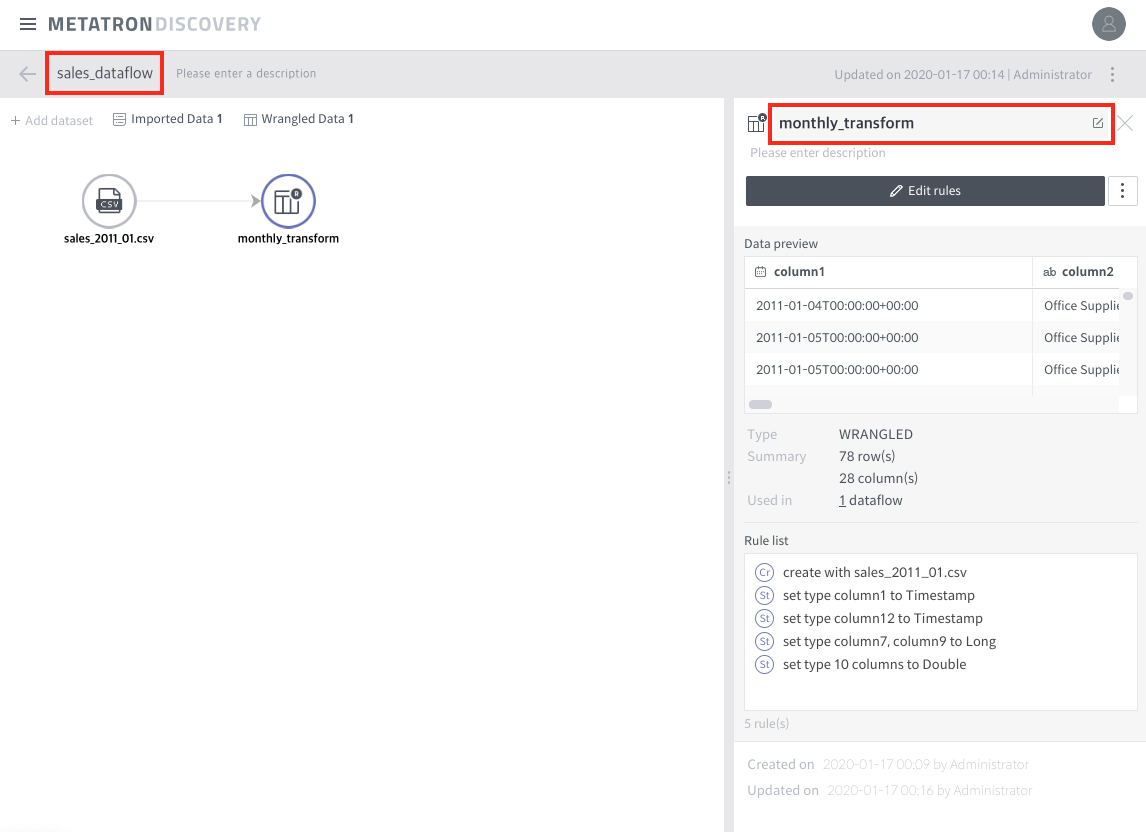
Use preptool for dataset swapping
^C # cd /tool # ./preptool -f /sample/sales_2011_02.csv # ./preptool -F sales_dataflow -o sales_2011_01 -n sales_2011_02.csv
Then you’ll see:
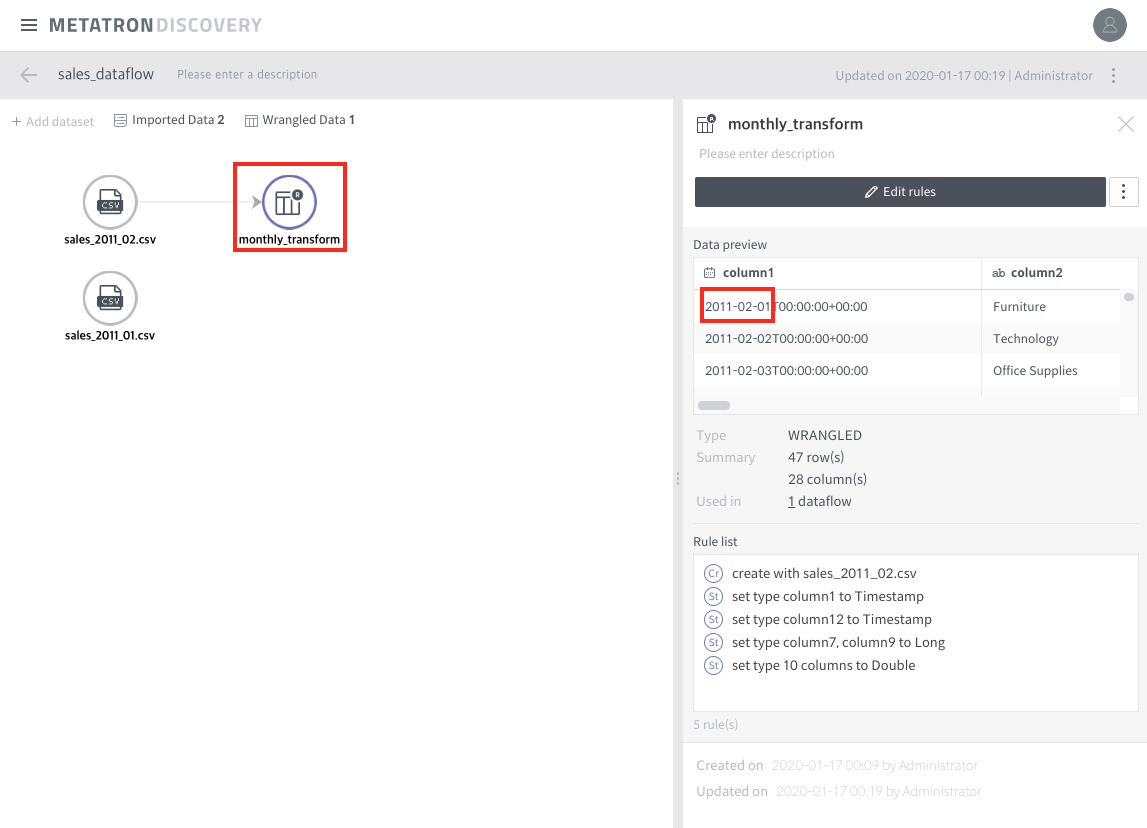
# ./preptool -f /sample/sales_2011_03.csv # ./preptool -F sales_dataflow -o sales_2011_02 -n sales_2011_03.csv
Once again:
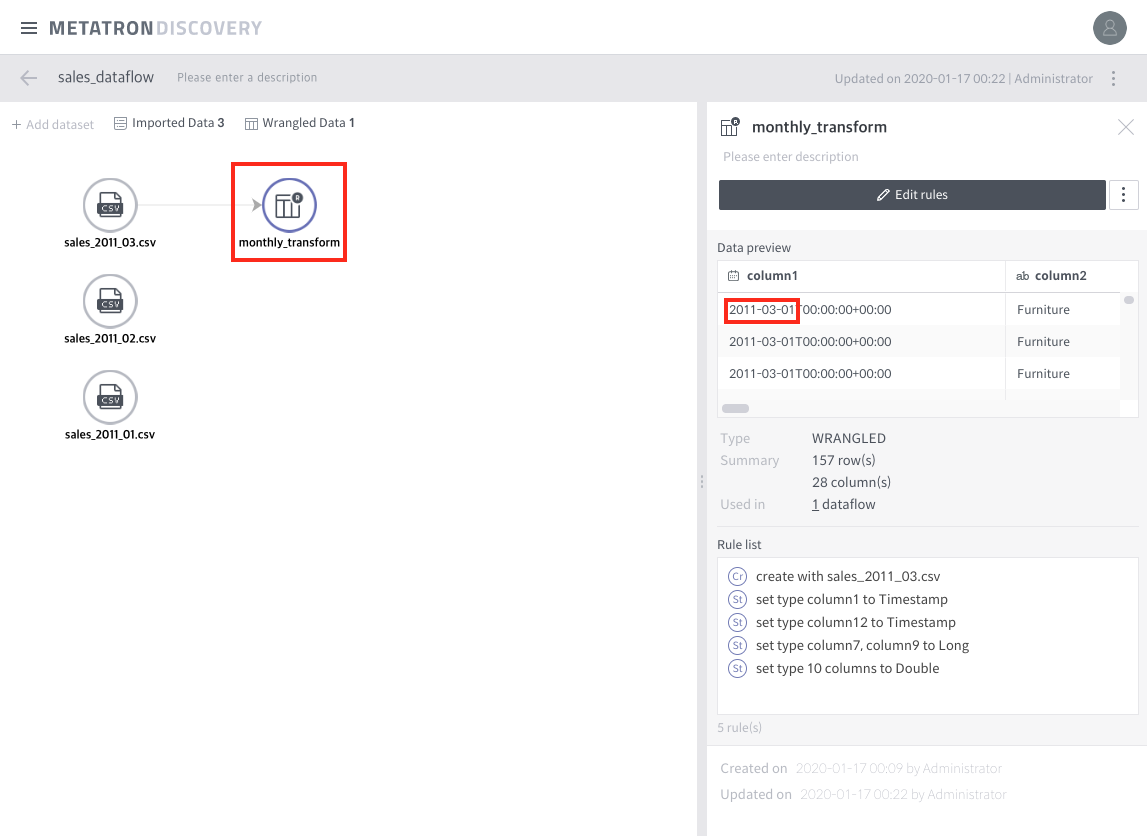
Generating a snapshot with CLI
# ./preptool -w monthly_transform -s 2011_03_report -t /2011_03_report.csv # tail /2011_03_report.csv … "2011-03-31T00:00:00+0000","Office Supplies","San Francisco","United States","Alex Avila","CA-2011-128055","94122","GBC DocuBind 200 Manual Binding Machine","2","West","Consumer","2011. 04. 05.","Standard Class","California","Binders","Shipped Early","null","null","37.7593","-122.4836","0.2","253.0","674.0","5.0","883.0","6.0","673.57",”37.5"
Wrap-up
- Create a new I.DS.
- Swap the old I.DS with the new I.DS.
- Generate a snapshot with the W.DS.
- Repeat above 3 steps with a scheduler program.
How about database type datasets?
Continuous integration with just incremental contents is very difficult problem both on files and tables. In the file case above, “incremental” integration problem is still open question. We need something like scheduler on this matter. I’ll write another article on this later.
One of our customers asked about how to apply source table changes to an existing snapshot table. In case tables were not too big or the SLA is not too tight, I suggest you to transform source datasets and overwrite the snapshot again.
To sum up,
- Suppose a source table is updated continuously.
- Build a nice dataflow with the table.
- Generate a snapshot.
- Repeat with a desirable interval. For stagedb type, the existing table will be overwritten. For file type, you should delete the old snapshos manually on demand.
If you want incremental integration, you should create different query type datasets for every iteration. For stagedb type, use “append” option in snapshot generation pop-up page. For file type, the new snapshot will contain only the result from the new dataset. Again, I do not recommend this for small tables or less-time-critical jobs.